Automatizando a análise de dados com Pipelines no Fabric
Dashboard atualizado todo dia de manhã...
2/3/2026
Imagine que um gerente precisa analisar o desempenho de vendas diariamente às 8h em um dashboard para definir as prioridades de estoque e distribuição de produtos. Para que o dashboard esteja atualizado à tempo, os dados brutos das transações precisam ser extraídos de sistemas de vendas, limpos e carregados em um lakehouse durante a madrugada.
Se esses processos forem configurados em plataformas diferentes ou sem uma conexão lógica entre eles, existe o risco de o Power BI iniciar seu processo de atualização antes que o tratamento dos dados tenha terminado. Isso resultaria em um dashboard com informações defasadas ou inconsistentes, o que prejudica a decisão sobre quais produtos estocar ou distribuir.
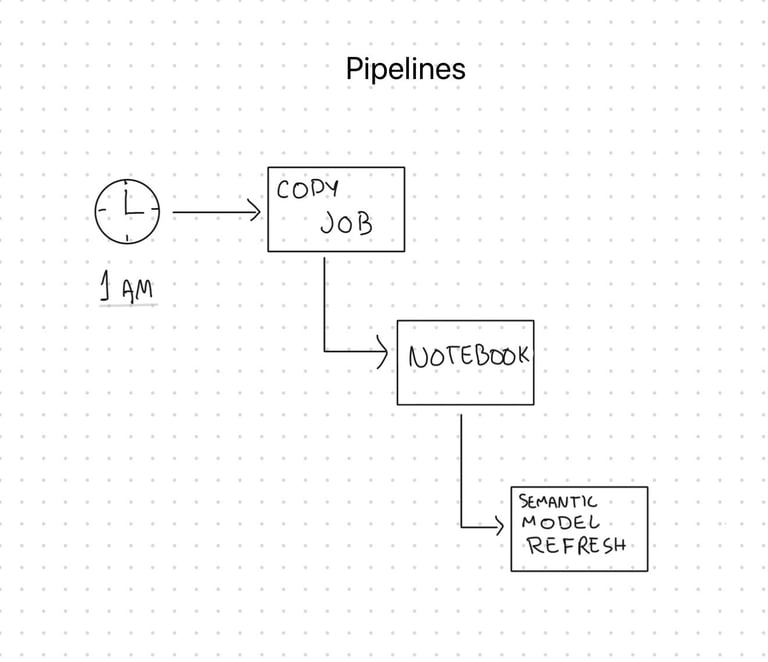
O Fabric resolve essa situação através de uma função chamada Pipelines. O pipeline funciona como um gerenciador de tarefas, que coordena a execução de cada etapa do processo de ETL (extração, transformação e carregamento). É o que faz o dado sair de um ponto A (sistemas "fontes de dados") até ir para um ponto B (os visuais de dados no dashboard).
Um pipeline é composto de atividades. Cada atividade configurada em um pipeline é responsável por uma etapa do processo, desde (1) iniciar a extração dos dados de sistemas externos em um horário definido, (2) acionar um Notebook para realizar transformações e processamento das tabelas, até (3) atualizar o modelo semântico do Power BI.
Essa automação garante que o dashboard esteja disponível na hora marcada e contenha apenas dados que foram processados corretamente. Caso ocorra uma falha em qualquer etapa anterior, a atualização do Power BI não é disparada (e você é notificado por email sobre o erro). Os pipelines são a peça fundamental para garantir que decisões sejam tomadas com base em fatos atualizados.