Quando usar Spark para escalar a análise de dados?
Do Excel travado ao processamento distribuído…
1/25/2026
A análise de dados pequenos funciona mais ou menos assim: baixa um arquivo, abre como planilha no Excel, seleciona alguns filtros, busca uma resposta e apresenta os resultados no PowerPoint. Quando você trabalha com poucos dados, o seu computador pessoal com 8GB de RAM é mais do que suficiente, e o Excel resolve a maioria dos problemas.
No entanto, quando você trabalha com volumes de dados maiores ou análises mais complexas, a realidade é outra. São milhares de linhas processadas diariamente, centenas de colunas, múltiplas fontes de dados. Nesse nível, o Excel atinge seu limite e até Pandas começa a falhar. Essas ferramentas travam porque tentam carregar todos os dados na memória de uma vez só. Quando a quantidade de dados é maior que a capacidade do processador, tudo trava.
Isso acontece na prática em agências de marketing de grande porte e até mesmo com infoprodutores que operam em larga escala. Imagine 4 lançamentos de +$1M por ano, incontáveis campanhas de perpétuo, várias plataformas e páginas, tudo isso mais CRM e sistema de vendas… uma hora trava.
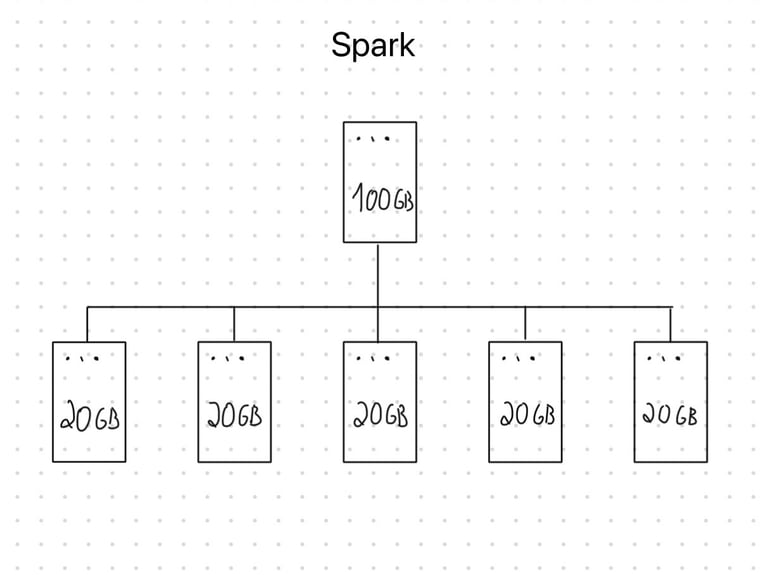
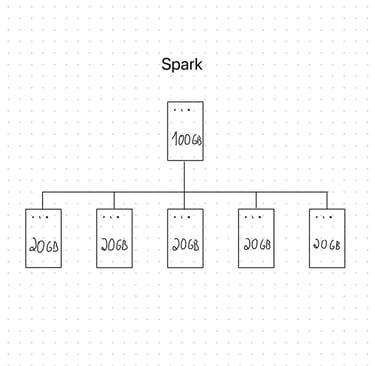
Uma das soluções para processar vários GBs/TBs de dados é recorrer ao processamento distribuído por meio do Spark. Imagine que um computador demora 10h para processar um arquivo de 100GB sozinho. Usando Spark, essa tarefa é dividida entre múltiplos “computadores paralelos”, chamados “nodos”. Se tivermos 5 nodos trabalhando ao mesmo tempo, em vez de um só, a tarefa que levaria horas pode ser concluída em minutos. De maneira bem simples, é o mesmo que comparar uma pessoa carregando 100 tijolos sozinha com uma equipe de 5 pessoas carregando 20 tijolos cada uma.
O Microsoft Fabric permite que você use Spark. Basta abrir um notebook com Spark pré-configurado e escrever o código em PySpark ou Spark SQL. A partir daí, você pode utilizar Spark para ler arquivos do seu lakehouse (JSONs, CSVs), transformar esses dados em dataframes, realizar análises complexas e salvar o resultado em uma tabela Delta para alimentar dashboards no Power BI.